En todo proyecto de software existe la necesidad de tener una adecuada gestión de los proyectos, para esto se debe contar con el personal capacitado, seleccionar el mejor proceso de acuerdo al problema que se vaya a tratar, y por supuesto una excelente planificación, con el fin de obtener un producto a tiempo y de calidad.
Cuando se desea realizar una gestión adecuada, eficaz y eficiente en la gestión de proyectos de software, es necesario que se ponga en funcionamiento cuatro características muy importantes en esta gestión, las cuatro P: personal, producto, proceso y proyecto. El gestor de proyectos muchas de las veces se olvida que el éxito o fracaso de los proyectos depende fundamentalmente del equipo humano con el que trabaje. El gestor debe basarse en procesos válidos y que verdaderamente le sirvan a su proyecto, no construir soluciones elegantes para problemas equivocados. Todo proyecto debe tener consigo una planificación previa, no se debe aventurar al éxito sin antes conocer los beneficios, contras y coste de cada uno de los proyectos. La ejecución de las cuatro características marcará el rumbo del éxito del gestor y de sus proyectos.
EL PERSONAL
El factor humano siempre será el más importante en el desarrollo de soluciones software, muchos empresarios famosos, líderes de empresas tecnológicas, coinciden que el éxito que han alcanzado sus empresas no se debe a las herramientas que utilizan, es la gente y el trabajo en equipo.
El Instituto de Ingeniería de Software, al ver la importancia que tiene el factor humano en la construcción del software, ha desarrollado un modelo de madurez de la capacidad de gestión del personal, esto con el fin de ayudar a las organizaciones de software a incrementar la rapidez en el desarrollo de proyectos cada vez más complejos.
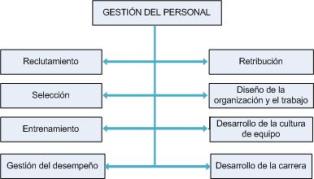
Al aplicar el modelo, la organización lograr atraer personal talentoso e inteligente que desea superarse y sobre todo, desea participar y trabajar en equipo para la consecución de los proyectos en los que participe. El reclutamiento y selección es fundamental en la gestión del personal, aquí se ve realmente cuáles son las personas que están en la capacidad de aportar a la organización, y no sólo eso, también se ve si pueden trabajar bajo presiones y en equipo. Para que el personal trabaje con ganas y pueda quedarse por un largo tiempo en la organización, sobre todo aquellos talentosos que siempre generan ideas innovadoras, deben ser motivados, sea esto económicamente, o con el buen trato de parte de sus superiores.
Es importante medir el desempeño del personal, así el gerente o dueño puede darse cuenta lo que realmente hacen sus trabajadores, es decir, si estos participan activamente en los proyectos que se están generando. A partir de esto, el gerente o dueño puede darse cuenta de que el equipo de trabajadores tiene suficiente capacidad y la responsabilidad de desarrollar sus tareas, o también, que a su gente le falta motivación y necesita algún estímulo para mejorar su rendimiento.
El proceso de software está integrado por participantes, líderes de equipo, etc. Los participantes se los puede clasificar en cinco categorías:
Gestores ejecutivo: Definen los aspectos del negocio.
Gestores del proyecto: Planifican, motivan, organizan y controlan a los profesionales que construyen el software.
Profesionales: Proporcionan las habilidades técnicas necesarias.
Clientes: Especifican los requerimientos.
Usuarios finales: Interactúan con el software.
Los líderes de equipo son difíciles de conseguir en el proceso de software, por lo general las personas no tienen la capacidad para trabajar con el personal. El líder debe ser capaz de motivar al personal técnico para que produzca lo mejor en base a su capacidad. La organización es fundamental en un proceso, el líder debe adecuar los procesos para generar un producto final excelente. Lo más importante, debe generar nuevas ideas, ideas innovadoras que ayuden a su equipo y les permita dar solución a problemas sumamente complejos o darle un valor agregado al producto.
El equipo de software debe ser uno solo, es decir, funcionar como conjunto, apoyarse mutuamente con el fin de logar el cumplimiento de los objetivos planteados. Todos los miembros del equipo deben tenerse confianza y distribuir la carga de trabajo según el problema que se esté tratando. No todo equipo es eficiente, pero se puede logar esto con la suficiente motivación y el apoyo de un buen gestor de proyectos.
EL PRODUCTO
Muchas veces cuando un cliente pide que le construyan una solución, siempre pregunta ¿cuánto me va a costar? Pues bien, todo producto requiere estimaciones cuantitativas y una adecuada planificación. Una adecuada recolección de información y un análisis detallado de los requerimientos proporciona la información necesaria para dar una estimación del costo del producto. Antes de planear un proyecto, se debe establecer los objetivos y el alcance que tendrá el proyecto, además de sus restricciones técnicas y de gestión. Con una buena planificación se puede estimar el tiempo que tomará desarrollar o construir el producto y redimensionar el valor cuantitativo del producto.
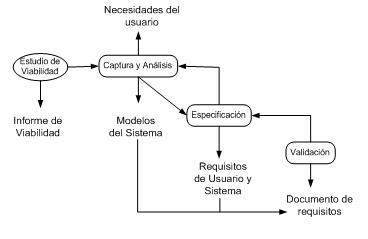
El desarrollador del software debe reunirse con el cliente las veces que sean necesarias para definir el dominio y los objetivos del producto. Esta actividad, comienza con la aplicación del proceso de ingeniería de requisitos; captura, análisis y, validación y verificación.
Definidos los objetivos y el dominio del producto se determina soluciones alternativas y viables, estas soluciones permitirán a los gestores del proyecto seleccionar las mejores opciones que convengan para cumplir con las restricciones que tenga la construcción del producto, sean estas de tiempo, presupuestarias, de personal, etc.
Para lograr rapidez en la construcción del producto, se debe dividir la carga de trabajo entre el equipo de desarrollo, es decir, dividir el problema. Esto, con el fin de desarrollar con mayor eficiencia y eficacia y en el tiempo acordado con el cliente, el producto.
EL PROCESO
El proceso del software proporciona un marco de trabajo desde el cual se puede establecer un plan detallado para la construcción del software. Todas las actividades del marco de trabajo se las pueden aplicar a la mayoría de proyectos de software, sino es a todos. El equipo de desarrollo debe elegir el proceso adecuado y que le permita obtener una solución o producto que satisfaga las necesidades o requerimientos del cliente.
El gestor del proyecto debe elegir el modelo de procesos adecuado para ser aplicado en la construcción del software, y el adecuado para:
– Los clientes que han solicitado el producto y el personal que hará el trabajo.
– Las características del producto.
– El ambiente del proyecto en el que trabaja el equipo de desarrollo del software.
Seleccionado el modelo de procesos, se desarrolla una planeación preliminar del proyecto basado en las actividades del marco de trabajo. Esta planeación comienza con la combinación del producto y el proceso. Cuando el equipo de desarrollo de software ha definido correctamente el modelo proceso, este debe ser flexible y adecuado para el proyecto. El proceso se puede descomponer para logar ejecutar correctamente las actividades y tareas del marco de trabajo. Las actividades que se deben desarrollar son:
– Desarrollar una lista de conflictos que deben clasificarse.
– Reunirse con los clientes para abordar los conflictos que deben clasificarse.
– Desarrollar en conjunto un enunciado del ámbito.
– Revisar el enunciado del ámbito con todos los implicados.
– Modificar el enunciado del ámbito según lo requiera.
EL PROYECTO
Cuando se gestiona un proyecto exitoso, es necesario entender que este puede llegar a fracasar. Según John Reel, existen 10 razones por las cuales un proyecto puede fracasar:
1. El personal de software no entiende las necesidades del los clientes.
2. El ámbito del producto está mal definido.
3. Los cambios se gestionan mal.
4. La tecnología elegida cambia.
5. Las necesidades comerciales cambian.
6. Los plazos de entrega no son realistas.
7. Los usuarios se resisten a la utilización del software.
8. Se pierde el patrocinio.
9. El equipo del proyecto carece de personal con las habilidades apropiadas.
10. Los gestores evitan las mejores prácticas y las lecciones aprendidas.
Para tener éxito en la consecución de un proyecto es necesario comenzar con pie derecho, esto se lo logra trabajando duro para entender el problema y dar una solución adecuada. Se debe rastrear el proyecto conforme se elabora el producto y se aprueba por parte del grupo de control de calidad. Es importante que el gestor del proyecto tome decisiones inteligentes para no poner en riesgo el desarrollo de la solución. Por último, se debe analizar los resultados obtenidos para obtener la experiencia necesaria en la construcción de otros proyectos.